4.3 Estadísticas descriptivas¶
Cómo realizar estadísticas descriptivas usando pandas (.min, .max, .std, .value_counts)¶
Mira este video de 6:01 a 8:06
Para español, haga click en configuración, seleccione “español” debajo de los subtítulos.
Traducción por Guillermo Rodríguez Guerrero (UNAM ENES León, México).
# Para reproducir el siguiente tutorial, presiona shift + enter
from IPython.display import YouTubeVideo
from datetime import timedelta
start=int(timedelta(hours=0, minutes=6, seconds=1).total_seconds())
end=int(timedelta(hours=0, minutes=8, seconds=6).total_seconds())
YouTubeVideo("jEQRU55x0e4",start=start,end=end,width=640,height=360)
La siguiente es una transcripción del video.
💡 Recuerde: Importe
pandasy lea el conjunto de datos a continuación para completar esta lección
# Importe pandas
import pandas as pd
# Decargue el conunto de datos del
# Jupyter Book para leer localmente o
# leer desde GitHub, a continuación:
data = pd.read_csv('https://raw.githubusercontent.com/DanChitwood/PlantsAndPython/master/co2_mlo_weekly.csv')
A continuación, veamos cómo realizar algunas estadísticas descriptivas en pandas, cosas como encontrar mínimos, máximos, desviaciones estándar, cuántos hay de cada nivel de factor.
Y esto es increíblemente simple. Acabas de ver que podemos referirnos a una columna específica usando un string. Digamos que queremos partes de CO2 por millón, pero queremos el valor mínimo de partes de CO2 por millón para esa columna. Entonces nos referimos a la columna específica y todo lo que hacemos es agregar “.min” como una función. Y obtenemos que el mínimo es 402,76.
# Hay una serie de funciones para realizar estadísticas simples en columnas.
# .min()
data['CO2ppm'].min()
402.76
Si queremos el máximo, hacemos lo mismo: “.max”, obtenemos 415.39.
# .max()
data['CO2ppm'].max()
415.39
Si queremos la media, solo ponemos “.mean” y obtenemos 408, en algún lugar de entre ellos.
# .mean()
data['CO2ppm'].mean()
408.97705882352943
Y si queremos la mediana, usamos la función “.median” y también obtenemos algo en algún lugar entre el mínimo y el máximo.
# .median()
data['CO2ppm'].median()
409.01
Hay muchas de estas funciones y puedes utilizarlas rápidamente. Son muy útiles. Puedes usar “unique” para obtener los niveles de una columna, qué tipos de cosas diferentes hay en esa columna. Entonces, por ejemplo, si miramos la columna específica del mes, los diferentes niveles de esa columna son los meses del año.
# .unique() da los niveles de una columna, los diferentes valores
data['month'].unique()
array(['aug', 'sep', 'oct', 'nov', 'dec', 'jan', 'feb', 'mar', 'apr',
'may', 'jun', 'jul'], dtype=object)
También puede obtener cuántas cosas hay de cada uno. A esto se le llama recuento de valores. De nuevo por mes tal vez queremos obtener los recuentos de valor y puede ver cada mes que nos va a dar cuánto puntos de datos que hay para cada mes.
# .value_counts() devuelve cuántos puntos de datos hay para cada nivel
data['month'].value_counts()
oct 62
dec 62
jan 62
mar 62
may 62
sep 60
nov 60
apr 60
jun 60
jul 58
feb 56
aug 50
Name: month, dtype: int64
Hay muchas funciones realmente útiles. Algunos incluso grafican. Por ejemplo, “hist”, “histogram” te dará un histograma. Puedes ver que obtenemos un histograma de las partes de CO2 por millón.
# .hist() devolverá un histograma
data['CO2ppm'].hist(bins=10) # have to shift-enter twice
<AxesSubplot:>
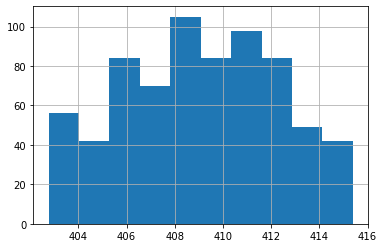
Así que así fue como al referirse simplemente a los nombres de columnas y luego usando funciones y pandas puedes obtener parámetros estadísticos muy básicos.